The rise of big data and data science has made storage and retrieval critical in data engineering. Data engineers play a crucial role in designing and developing pipelines to collect, manipulate, store, and analyze data. With the world projected to produce 463 exabytes per day by 2025, data engineering & analytics professionals have the opportunity to make a tangible difference.
Data engineering originally focused on loading external data sources and designing databases. However, it has now evolved to handle the volume and complexity of big data. In this context, data storage and retrieval are essential for the successful functioning of the pipeline and for utilizing and analyzing the data effectively.
Meanwhile, new and different data storage technologies continue to emerge. Hence, data engineers face the challenge of selecting the most suitable technology that meets their specific needs.
While SQL databases like PostgreSQL, MSSQL, and MySQL are widely known among engineers for their structured, relational data tables with row-oriented storage, new advancements such as Microsoft Fabric are introducing open industry standard formats and enhancing integration and accessibility for data analytics and data engineering.
Transform Your Quality Engineering With AI, Automated Frameworks & CI/CD Integration
Join Our Webinar to Unlock the Power of Next-generation AI at Work
 Register now
Register now
What Microsoft Fabric Offers To Data Engineering and Analytics Organizations
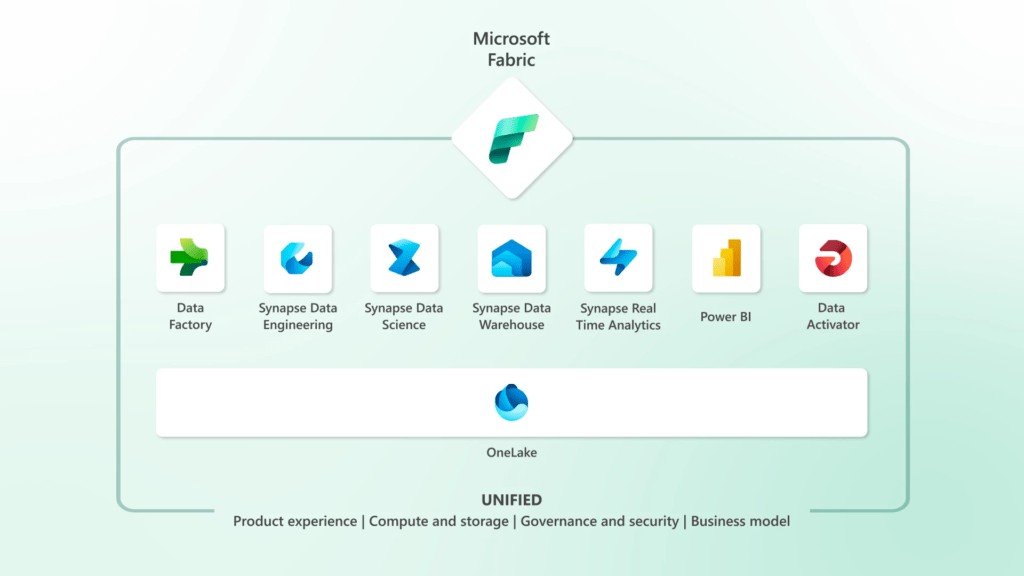
Microsoft Fabric aims to lead the entire data analytics industry, not just in business intelligence and analytics. Thus, Fabric provides a range of combined experiences, including data integration powered by Data Factory, data engineering and data warehousing powered by Synapse. Accompanied by data science and real-time analytics experiences, and business intelligence (BI) utilizing Power BI.
As a data engineering and analytics organization, implementing Microsoft Fabric offers several benefits. Optimize your data engineering and analytics operations and maximizing efficiency using these features:
A Single Consolidated Copy Concept:
By adopting Microsoft Fabric, you can eliminate redundant data storage. This approach helps reduce costs by eliminating the need for multiple copies of the same data. You can optimize your storage infrastructure and avoid unnecessary expenses.
Affordable Data Engineering & Analytics Solutions
Microsoft Fabric not only reduces storage costs but also helps lower implementation expenses. With its streamlined data storage approach, you can eliminate complex and costly data replication processes. And, this cost-saving aspect of Microsoft Fabric enhances your organization’s financial efficiency and reduces your overall data engineering and analytics costs.
Smaller and Smarter Data Engineering Cycle:
Implementing Microsoft Fabric enables a more efficient and streamlined data engineering process and analytics. Eliminating redundant data storage and simplifying processes allow for a smaller and smarter data engineering cycle. This results in improved productivity, faster data processing, and shorter development cycles. Therefore, ultimately helping your organization achieve its goals more effectively.
Increased Visibility:
Microsoft Fabric provides improved visibility into data and the data engineering and analytics process. Enhanced monitoring and reporting capabilities give you valuable insights into your data assets and the underlying engineering activities. This increased visibility empowers your data engineers to make informed decisions. Additionally it optimizes processes, and ensures data quality and integrity throughout the data lifecycle.
Reduced Computing Costs:
Unnecessary data replication is minimized with Microsoft Fabric, leading to cost savings on computing resources. By avoiding redundant computing tasks, you can optimize resource allocation and achieve significant cost savings in your data engineering operations. This contributes to improved cost-effectiveness and efficient utilization of computational resources.
Read More – Databricks Vs Snowflake: Choosing Your Cloud Data Partner
Microsoft Azure Transforming Computing Cost Models With General Availability
Experience a groundbreaking shift in computing cost models as Microsoft prepares to unveil innovative solutions upon General Availability (GA). Microsoft’s better-integrated environment eliminates the need for additional cloud and technology infrastructure. Moreover, seamlessly leverage the open standard format while harnessing the power of a wide array of tools within the Azure ecosystem.
Azure, Microsoft’s comprehensive cloud platform comprising over 200 products and cloud services, empowers you to bring your solutions to life, tackling today’s challenges and paving the way for the future. Azure in particular, has revolutionized the way organizations work with data engineering and analytics.
With an extensive portfolio of over 90 compliance offerings, Azure boasts the largest compliance portfolio in the industry. 95% of Fortune 500 companies rely on Azure for their business needs.
Also Read: Microsoft Fabric Vs Databricks: A Comparison Guide
Microsoft Fabric’s Impact on Data Engineering and Analytics
Microsoft Fabric revolutionizes BI, analytics, and data warehousing products, offering numerous benefits to Power BI users. Power BI customers can seamlessly access the functionalities they currently enjoy.
For Power BI Premium customers, enabling the Fabric tenant setting allows them to utilize the unified capacity model. In turn, empowering them to leverage any of the new workloads. Power BI Pro customers can also access these features through capacity trials. This allows them to optimize their data engineering and analytics capabilities.
Fabric introduces exciting Power BI Premium exclusive features. Powered by AI, Copilot integrates large language models into Power BI. Copilot enables users to describe the visuals and insights they seek while Copilot takes care of the rest. Moreover, it allows users to create tailored reports, generate and edit DAX calculations. Simultaneously, it helps create narrative summaries, and ask questions about data using conversational language.
Data Standardization for Data Engineering & Analytics
Fabric standardizes on open data formats like Delta Lake and Parquet, reducing data duplication and management while offering high-performance querying directly against OneLake through Direct Lake mode. This eliminates the need for data movement and refresh management.
Seamless Collaboration with Git Integration
Collaboration is enhanced with Git integration, enabling seamless collaboration with development teams. Power BI content can be connected to Azure DevOps repositories, facilitating change tracking, version history, and merging updates. Developers can utilize Power BI Desktop to author report and dataset metadata files in source-control friendly formats. Thus, enabling multiple developer collaboration and source control integration.
Simplified Data Management with Microsoft Fabric
Fabric provides end-to-end governance across Power BI, Synapse, and Data Factory on a unified SaaS platform. Data teams can collaborate in a single workspace, manage user roles, ensure data protection and compliance, and utilize administration and governance tools with cloud engineering. The OneLake Data Hub simplifies data discovery and management, allowing users to centrally explore and build upon existing data projects. This allows for more collaborative data engineering and analytics processes.
Simplified Resource Management and Cost Efficiency
With Fabric’s universal compute capacities, purchasing and managing resources become simpler. A single pool of compute powers all Fabric experiences, reducing costs as unused capacity can be utilized by other workloads. Moreover, Power BI Premium customers can access new Fabric experiences with existing SKUs. New Fabric SKUs will be available for purchase in the Azure portal starting June 1, granting access to all experiences. So, this will significantly lower your organization’s data engineering and analytics costs.
Take Advantage of Microsoft Fabric and Unleash New Frontiers in Data Engineering and Analytics with FLIP
Embracing limitless possibilities, Microsoft Fabric has positioned Microsoft ahead of other cloud and data storage solutions, such as Google Cloud, AWS, Redshift, and Snowflake.
FLIP, our state-of-the-art, zero-code DataOps platform, is designed for agile and efficient data processing. And, now proudly supports Microsoft Fabric as both data source/destination. This integration represents a significant enhancement in FLIP’s capabilities, bringing together its robust data processing and transformation prowess with Microsoft Fabric’s advanced data engineering and analytics tools. The strategic alignment of FLIP with Microsoft Fabric underscores our commitment to providing our clients with cutting-edge data solutions, optimizing their data workflows, and enabling more insightful analytics.
Key Features and Benefits of the Integration
- Robust Data Engineering Capabilities: Leveraging Microsoft Fabric’s comprehensive suite of services, FLIP enhances its data engineering solutions. This includes advanced features for data science, business intelligence, real-time analytics, and efficient data migration.
- Enhanced Analytics and Business Intelligence: With Microsoft Fabric’s sophisticated analytics tools, FLIP users can unlock deeper insights and more powerful business intelligence capabilities. This integration facilitates a richer understanding of data, empowering businesses to make informed decisions.
- Streamlined Data Processes: The synergy between FLIP and Microsoft Fabric simplifies and streamlines data processes. This integration ensures seamless data flow and management, reducing complexities in handling large datasets and diverse data sources.
- Scalable and Flexible Solutions: FLIP, integrated with Microsoft Fabric, offers scalable solutions that adapt to varying business needs. Whether for small-scale projects or large, complex data environments, this integration ensures flexibility and scalability.
- Secure Data Management: Prioritizing data security, the integration offers robust protection mechanisms, ensuring the safety and integrity of your data throughout the data lifecycle.
Don’t miss out on this exclusive opportunity to be a part of the Microsoft Fabric revolution. Join the preview and stay ahead of the competition in data integration, artificial intelligence, and business intelligence.
Sign up today and be a part of the remarkable advancements that Microsoft Fabric will bring to the realm of data analytics.
FAQ
Why do I need Microsoft Fabric?
Microsoft Fabric simplifies your data journey, consolidating disparate tools into a single, integrated platform. This eliminates the hassle of managing multiple systems and streamlines data warehousing, analytics, and reporting. Ultimately, it saves you time, reduces costs, and empowers better, faster decision-making based on unified data. It’s your one-stop shop for all things data.
What is the difference between Microsoft Fabric and Snowflake?
Microsoft Fabric is a unified analytics platform, offering a single workspace for data integration, warehousing, processing, and visualization *within* the Microsoft ecosystem. Snowflake, conversely, is a cloud-based data warehouse focusing primarily on data storage and querying, often requiring integration with other tools for a complete analytics workflow. Essentially, Fabric aims for all-in-one simplicity, while Snowflake excels as a powerful, scalable data warehouse component in a broader data stack. The key difference boils down to scope: integrated platform versus focused data warehouse.
Is Microsoft Fabric low code?
Microsoft Fabric isn’t strictly “low-code” in the traditional sense, it offers a range of tools catering to different skill levels. While it simplifies many data processes with intuitive interfaces, it also allows for deep customization and scripting for advanced users. Think of it as a spectrum—offering low-code capabilities alongside full-code options depending on your needs.
What is the competitor of Microsoft Fabric?
Microsoft Fabric doesn’t have one single, direct competitor, but rather faces a fragmented landscape. Its all-in-one approach challenges separate tools like Snowflake, Databricks, and Tableau, each excelling in specific areas. Therefore, the “competition” is more of a comparison across best-of-breed solutions versus a singular alternative. Choosing the right alternative depends entirely on specific needs and existing infrastructure.
Is Microsoft Fabric cloud-based?
Yes, Microsoft Fabric is entirely cloud-based. This means all its services, from data warehousing to analytics and visualization, run on Microsoft’s Azure cloud infrastructure. You don’t manage any on-premises servers; everything is accessed and managed through the cloud portal. This offers scalability, accessibility, and simplified administration.
What is Microsoft Fabric vs Azure?
Microsoft Fabric is a unified analytics platform *built on top of* Azure. Think of Azure as the foundation—the cloud infrastructure—while Fabric is a pre-built house specifically designed for data analytics, offering integrated tools for data ingestion, transformation, storage, and visualization. Azure provides the raw power; Fabric offers a streamlined, all-in-one experience. It’s like comparing bricks and mortar to a finished building.
Follow us on LinkedIn and Twitter for insightful industry news, business updates and all the latest data trends online.

