Did you know that around 22% of companies worldwide are vigorously trying to integrate AI into a diverse range of technology products and business processes for enhanced business performance? Artificial intelligence (AI) has come a long way in recent years, with large language models (LLMs) revolutionizing the field of natural language processing. These powerful models have been proficient in tasks such as text generation, language understanding, and knowledge representation. However, there were questions about their factual accuracy and limited context-awareness as their knowledge is primarily derived from their training data. Retrieval Augmented Generation (RAG) tackles this limitation and ensures better outcomes.
Retrieval Augmented Generation (RAG) is a groundbreaking AI technique that can transform how we interact with and leverage artificial intelligence. It combines the capabilities of LLMs with the precision and contextual awareness of information retrieval, enhancing the potential and integrity of AI systems. RAG addresses the limitations of traditional AI models, enabling them to provide more accurate, relevant, and up-to-date information.
The significance of RAG lies in its ability to revolutionize various applications, from conversational AI and question answering to content generation and decision support. By unlocking the potential of this transformative approach, we can pave the way for more engaging, trustworthy, and impactful interactions between humans and machines.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a technique that combines retrieval and generation functionalities to enhance the accuracy and reliability of generative AI models with facts fetched from vast data sources. It’s a two-pronged approach that combines the power of retrieval and generation functionalities. The first component, the retrieval system, acts as a super-powered search engine, scouring vast data sources – like Wikipedia or a company’s internal knowledge base – to find information directly relevant to the user’s query.
What LLM Challenges Does Retrieval Augmented Generation Address?
AI has witnessed a surge in the development of powerful language models (LLMs) capable of generating human-quality text, translating languages, and writing creative content. However, these models often have a critical limitation: they need access to factual, up-to-date information beyond the data they were trained on, mainly when dealing with complex, open-ended queries. This can lead to outputs that are factually incorrect and irrelevant to the context.
RAG addresses the limitations of LLMs and enhances their capabilities by integrating a retrieval mechanism. RAG-powered AI systems can provide more accurate, contextual, and up-to-date responses, seamlessly blending the generative capabilities of LLMs with the precision of information retrieval.
For better understanding, let’s say you’ve asked a traditional LLM, “What’s the population of India?” It may take information from its training data, which could be outdated or inaccurate. But a RAG system would go a step further. It would check a reliable source and confidently give a factually accurate answer.

Key Components of Retrieval Augmented Generation
The core mechanics of Retrieval-Augmented Generation (RAG) can be divided into two key phases: the retrieval phase and the content generation phase.
Retrieval Component
The RAG model uses a specialized retrieval mechanism to identify the most relevant information from vast data sources, such as knowledge bases, databases, and documents. It converts user queries into a numeric format and compares them to vectors in a machine-readable index, retrieving the related data when it finds a match.
The retrieval mechanism in RAG uses various techniques, such as neural information retrieval, knowledge graph-based retrieval, or a combination of both. These methods leverage advanced natural language processing and machine learning algorithms to analyze the input query, understand its context, and efficiently search the knowledge base to find the most relevant and up-to-date information.
Generation Component
Once the relevant information has been retrieved, the RAG model leverages large language models’ power to generate a coherent and informative response. This component uses retrieved information to generate human-like text. It combines the retrieved words and its response to the query into a final answer, potentially citing sources the embedding model found/ The retrieved information is seamlessly integrated into the content generation process, allowing the AI system to produce a response that is both factually correct and tailored to the specific needs and context of the user.
This integration of retrieval and content generation enables the AI system to draw upon a vast knowledge base while maintaining LLMs’ fluency and natural language capabilities. This results in generating a response that is accurate, informative, and contextually relevant.
Read More – Everything You Need to Know About Building a GPT Models
How Does a Retrieval Augmented Generation (RAG) work?
The workflow of a Retrieval-Augmented Generation (RAG) system involves several key steps that enhance the accuracy and reliability of generative AI models by combining retrieval and generation functionalities:
1. User Input
Users interact with the RAG system by asking questions or providing prompts. This initial step sets the stage for the system to understand the user’s query and initiate the process of retrieving relevant information.
2. Information Retrieval
The retrieval component analyzes the user input to identify key terms, concepts, and the overall intent behind the query. Based on the nature of the input, the system selects the appropriate data source for retrieval. This could be a general knowledge base like Wikipedia, a company’s internal database, or a curated collection of educational materials.
The retrieval component employs sophisticated algorithms to search the designated data source for information directly relevant to the user’s query. These algorithms might consider factors like keyword matching, semantic similarity, and document relevance ranking.
3. Feeding the LLM
The retrieved information is then processed to extract the most relevant and informative sections. This might involve techniques like summarization or information extraction.
The extracted information is often transformed into a format the LLM can understand and utilize effectively. This could involve converting the information into key-value pairs, highlighting specific sentences, or generating a summary document.
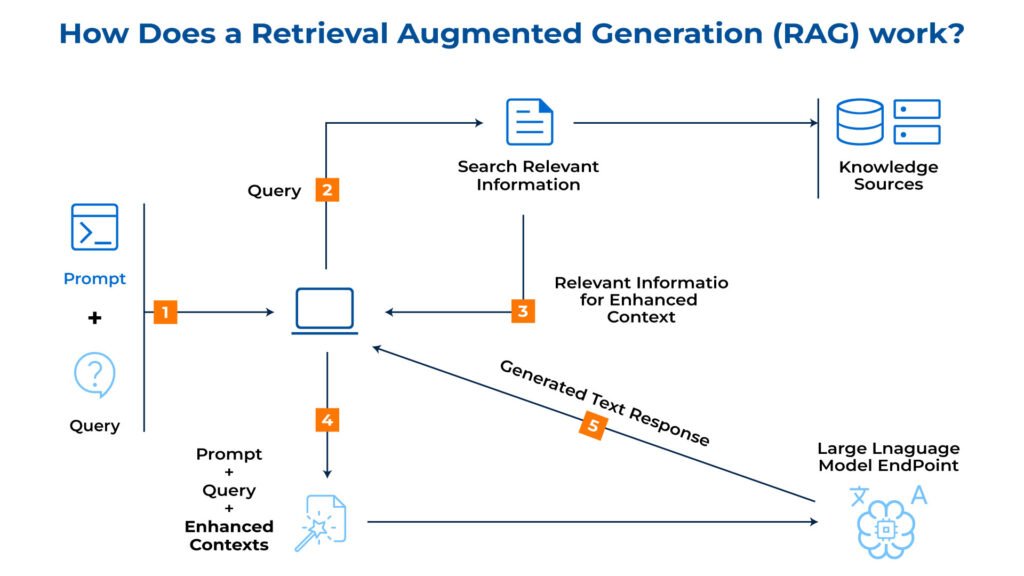
4. Generation with Augmented Knowledge
The LLM receives the user input and the structured knowledge representation from the retrieval component. The LLM can generate a more comprehensive and informative response with this newfound knowledge. It can incorporate factual data, relevant examples, or background information retrieved from the data source.
The LLM utilizes its language structure, grammar, and style knowledge to craft a human-like text output that fulfills the user’s intent. This could be a factual answer to a question, a well-structured blog post, or even a creative text format like a poem or a story.
5. Output
The final form of the output can vary, including answers, summaries, or creative text formats. The output of the Retrieval Augmented Generation (RAG) system is designed to provide users with accurate, context-aware and engaging responses that meet their information needs effectively. This ensures the generated text is coherent, fluent, and relevant to the user’s query, enhancing the overall user experience.

Implementing RAG: A Step-by-Step Guide
Retrieval Augmented Generation (RAG) offers a powerful approach to enhancing AI applications with real-world knowledge. However, implementing an RAG system requires careful planning and consideration. Here’s a detailed breakdown of the process with best practices to guide you:
1. Define Your Use Case and Goals
Identify the Need: The first step is clearly defining the problem you’re trying to solve with RAG. Are you aiming to improve chatbot accuracy, personalize learning experiences, or generate informative content?
Set Measurable Goals: Establish specific and measurable objectives for your RAG system. This could involve metrics like factual accuracy in generated text, user satisfaction with chatbot responses, or completion rates in e-learning modules.
2. Data Acquisition and Preparation
Choose the Right Data Source: Select a high-quality data source that aligns with your use case. This could be a public knowledge base, a company’s internal database, or a curated collection of relevant documents.
Data Cleaning and Preprocessing: Ensure your data is clean, consistent, and error-free. This might involve tasks like removing irrelevant information, correcting typos, and standardizing formatting.
Data Annotation (Optional): Consider annotating your data to improve retrieval accuracy for specific use cases. This involves labeling data points with relevant keywords or categories that aid the retrieval process.
3. Selecting and Fine-tuning the Retrieval Component
Retrieval Model Choice: Various retrieval models are available, each with its strengths and weaknesses. Popular choices include Dense Passage Retrieval (DPR) and Sentence-BERT. When selecting a model, consider factors like data size, desired retrieval accuracy, and computational resources.
Fine-tuning the Retrieval Model: Fine-tuning your retrieval model on your specific data source can significantly improve its performance. This involves training the model to identify information relevant to your use case.
4. Choosing and Fine-tuning the Generation Component
Large Language Model Selection: Select a large language model (LLM) that suits your needs. Popular options include GPT-3, Jurassic-1 Jumbo, and T5. When choosing, consider factors like the desired output format (text summarization, question answering, creative text formats) and computational resources.
Fine-tuning the LLM: Fine-tune your LLM on a dataset of text and code examples that align with your use case. This helps the LLM learn how to utilize retrieved information to generate the desired output format effectively.
5. System Integration and Testing
Integrate Retrieval and Generation Components: Connect the retrieval component with the LLM to create a seamless workflow. This involves defining how the retrieved information will be presented to the LLM for generation.
Rigorous Testing and Evaluation: Test your RAG system thoroughly with diverse inputs to ensure it functions as expected. Evaluate its performance based on your predefined goals and adjust parameters as needed.
Read More – Best Generative AI Tools For Businesses in 2024

Benefits of Using Retrieval Augmented Generation
Integrating retrieval and content generation in Retrieval-Augmented Generation (RAG) offers a range of benefits that make it a transformative approach to AI. Let’s explore these benefits in more detail:
1. Real-time Access to Information
Retrieval Augmented Generation (RAG) provides real-time access to information by leveraging the retrieval component, allowing for up-to-date and timely responses to user queries.
2. Enhanced Credibility and Transparency
RAG can cross-reference information from multiple sources to verify the validity of claims, enhancing credibility and transparency in decision-making processes, particularly in fields like ESG research and investment management.
3. Personalized and Contextual Insights
RAG-based systems can automatically cater to the specific needs of users, delivering personalized and contextual insights tailored to different professionals, such as PE analysts, risk managers, and compliance managers, enhancing decision-making processes.
4. Deeper Domain-Specific Coverage
By adaptively selecting the right knowledge base, RAG-based systems can offer more domain-specific expertise, providing deeper insights in areas like private company diligence, equity research, and niche sectors like healthcare.

5. Increased Usability and Precision
Retrieval Augmented Generation helps tailor responses based on user persona and context, ensuring precision in delivering relevant information and optimizing user productivity.
6. Reduced Bias and Errors
By curating retrieval sources, RAG-enabled models can reduce biases and errors present in training data, enhancing the reliability and accuracy of responses.
7. Reduced Retraining Needs
RAG’s ability to leverage external knowledge sources reduces the need for retraining, making it a more efficient and cost-effective solution for AI development. As new information becomes available or user needs evolve, RAG-powered systems can adapt without requiring a complete overhaul of their underlying architecture.
8. Addresses Misinformation
RAG’s ability to retrieve and integrate information from a knowledge base can also help address the challenge of Misinformation. By drawing upon authoritative and up-to-date sources, RAG-powered systems can provide responses that are grounded in factual information, reducing the risk of propagating false or misleading claims.
Read More – Google’s Gemini Pro vs. OpenAI’s GPT-4: A Detailed Review

Applications of Retrieval Augmented Generation
1. Content Creation
RAG can be used in content creation to generate factual and engaging content by retrieving relevant information from vast data sources, ensuring the accuracy and relevance of the generated content.
2. Chatbots and Customer Service
RAG-powered chatbots can provide more informative and helpful responses to user queries by accessing real-time, targeted information retrieval, enhancing the user experience, and improving the credibility and transparency of decision-making processes.
3. Summarization and Question Answering
RAG can improve the accuracy and efficiency of tasks, such as summarizing documents and answering questions based on the retrieved information, making it an effective tool for knowledge management and information retrieval.
4. Financial Services
RAG can be used in financial services, such as ESG research and investment management, to ensure timeliness and real-time access to information, enhancing credibility and transparency in decision-making processes.
5. Healthcare
RAG can be applied in healthcare to provide personalized and contextual insights tailored to different professionals, such as physicians and researchers, enhancing decision-making processes and improving patient outcomes.
6. Education
RAG can personalize learning experiences with AI tutors, providing context-aware and accurate information to students, making it an effective tool for enhancing the quality and reliability of educational content.
7. Legal Services
RAG can be used in legal services to provide authoritative answers that cite sources, making it an effective tool for legal research and decision-making processes.
8. E-Commerce
RAG can be used to analyze user reviews, competitor information, and product specifications. This allows for the generation of detailed and informative product descriptions that highlight each item’s specific advantages, leading to a more engaging shopping experience for consumers.
9. Scientific Research
RAG can be used to analyze scientific literature, identify relevant research papers, and even summarize key findings. This can save researchers valuable time and effort, allowing them to focus on groundbreaking discoveries and innovations.

Challenges of RAG Implementation
Though Retrieval-Augmented Generation (RAG) offers numerous benefits, there are also a few challenges that must be addressed:
1. Efficient and Scalable Retrieval Mechanisms
Developing retrieval mechanisms that can quickly and accurately identify the most relevant information from large knowledge bases can be very challenging. Additionally, it is important to ensure the scalability of these retrieval systems to handle growing volumes of data.
2. Seamless Integration with LLMs
Seamlessly integrating the retrieval component with the content generation capabilities of large language models is a complex task that requires innovative solutions to maintain the fluency and coherence of the generated responses.
3. Secure Handling of Sensitive Information
The deployment of RAG-powered systems requires the security of sensitive user data and the protection of privacy. Data analysis protocols and security measures must be implemented to build trust and maintain compliance with relevant regulations.
4. Responsible Data Sourcing
The knowledge bases used by RAG systems must be carefully curated to ensure that the information they contain is accurate, up-to-date, and ethically sourced without compromising individual privacy or perpetuating biases.
5. Maintaining Transparency in Decision-Making
Preserving the transparency and interpretability of the decision-making process in RAG-powered AI systems is essential for building trust and accountability. Users and stakeholders must be able to understand the reasoning behind the system’s responses and the sources of the information used.

Future Trends in Retrieval Augmented Generation
As the field of artificial intelligence continues to evolve, the future of Retrieval Augmented Generation (RAG) holds exciting possibilities. Researchers and developers are exploring various avenues to enhance further the capabilities and impact of this transformative approach to AI.
1. Advancements in Retrieval Mechanisms:
Neural Information Retrieval: Ongoing research and development in neural information retrieval can lead to more efficient and accurate retrieval mechanisms, enabling RAG-powered systems to identify relevant information from large knowledge bases.
Knowledge Graph-based Retrieval: Integrating knowledge graph-based retrieval techniques into RAG can enhance the system’s understanding of the semantic relationships between concepts, leading to more contextually relevant responses.
Multimodal Retrieval: Expanding RAG’s retrieval capabilities to include multimodal information, such as images, videos, and audio, can unlock new possibilities for more comprehensive and engaging AI interactions.
2. Integration with Emerging AI Techniques:
Reinforcement Learning: Combining RAG with reinforcement learning approaches can enable the development of AI systems that can continuously learn and improve their performance based on user feedback and real-world interactions.
Generative Adversarial Networks (GANs): Integrating RAG with GAN-based architectures can generate more realistic and coherent responses, further enhancing the user experience.
Transformer-based Models: Leveraging the latest advancements in transformer-based language models can improve the fluency, coherence, and contextual awareness of RAG-powered systems.
3. Improved Ethical Considerations
Bias Mitigation Strategies: Continued research and development in algorithmic bias detection and mitigation will be crucial in shaping the responsible and equitable deployment of RAG-powered systems.
Transparent and Accountable AI: Advancements in explainable AI techniques and the implementation of robust governance frameworks will be essential in ensuring the transparency and accountability of RAG-powered systems.
Privacy-preserving Mechanisms: Innovative approaches to data privacy and security, such as federated learning and differential privacy, can enable developing RAG-powered systems that respect individual privacy while still delivering valuable insights.

LLM Case Studies: How Kanerika Leveraged LLMs for Enhancing Business Performance
1. Enhancing Efficiency through LLM-Driven AI Ticket Response
Business Challenges
- Increasing expenses for technical support posed limitations on business growth, reducing available resources.
- Difficulty in retaining skilled support staff resulted in delays, inconsistent service, and unresolved issues.
- Repetitive tickets and customer disregard for manuals drained resources, hindered productivity, and impeded growth.
Kanerika’s Solutions
- Created knowledge base and prepared historical tickets for machine learning, improving support and operational efficiency
- Implemented LLM-based AI ticket resolution system, reducing response times and increasing customer satisfaction with AI for business
- Implemented AI for operational efficiency and reduced TAT for query resolution

2. Transforming Vendor Agreement Processing with LLMs
Business Challenges
- Limited understanding of data hampering efficient data migration and analysis, causing delays in accessing crucial information.
- Inadequate assessment of GCP readiness challenges seamless cloud integration, risking operational agility.
- Complexities in accurate information extraction and question-answering impacting the quality and reliability of data-driven decisions.
Kanerika’s Solutions
- Thoroughly analyzed data environment, improving access to critical information and accelerating decision-making.
- Upgraded the existing infrastructure for optimal GCP readiness, enhancing operational agility and transitioning to the cloud.
- Built a chat interface for users to interact with the product with detailed prompt criteria to look for a vendor.

Trust Kanerika to Elevate Your Enterprise Operations with RAG-powered LLMs
Kanerika, a globally recognized tech services provider, can elevate your enterprise operations with RAG-powered Large Language Models (LLMs). Leveraging cutting-edge technology expertise, Kanerika solves business challenges, driving innovation and growth.
With a proven track record in handling numerous LLM projects, Kanerika offers tailored tech solutions across diverse industries such as BFSI, healthcare, logistics, and Telecom. From data analytics and integration to Robotic Process Automation (RPA) and Generative AI, Kanerika’s services are designed to propel your business to the next level, ensuring efficiency, scalability, and success in the digital landscape.

Frequently Asked Questions
What is the difference between generative and retrieval chatbot?
Generative chatbots create new, original text responses based on patterns learned from their training data, like a creative writer. Retrieval chatbots, on the other hand, select the best pre-written response from a database, similar to a well-organized librarian finding the perfect book. This means generative models are more flexible but risk hallucinations, while retrieval models are accurate but less creative.
What is a RAG used for?
RAG, or Retrieval Augmented Generation, isn’t just about generating text; it’s about making that text *accurate* and *relevant*. It uses external knowledge sources to ground its responses, preventing hallucinations and ensuring factual outputs. Think of it as giving a large language model a powerful research assistant, leading to more reliable and trustworthy information. Essentially, it improves the quality and groundedness of AI-generated content.
What is the difference between generative model and retrieval model?
Generative models *create* new content by learning the underlying data distribution, like imagining a new picture similar to ones it’s seen. Retrieval models, conversely, find the *best existing* piece of content from a database that matches a given query, like searching for a similar picture in a library. Essentially, one hallucinates, the other recalls. The key difference lies in creation versus selection.
What is retrieval in data processing?
Retrieval in data processing is simply getting data back out. Think of it like finding a specific book in a giant library – you use a system (like a search engine or database query) to locate and access the information you need. It’s the crucial “read” operation, the inverse of storage. Efficient retrieval is key to making data useful.

