Imagine an artist skillfully expanding their canvas, adding strokes and colors to bring a masterpiece to life. Similarly, if you ask, “What is data augmentation?” the simple answer would be enriching the palette of machine learning algorithms by infusing datasets with variations and insights from real-life scenarios.
To make it simpler, let’s take another relatable example. You need a diverse set of cat images if you’re teaching a machine learning model to recognize cats. But what if your dataset contains primarily images of cats indoors, and your model encounters a cat outdoors with a completely different background? This is where the magic of data augmentation comes into play in deep and machine learning.
Fundamentals of Data Augmentation
Definition and Concepts
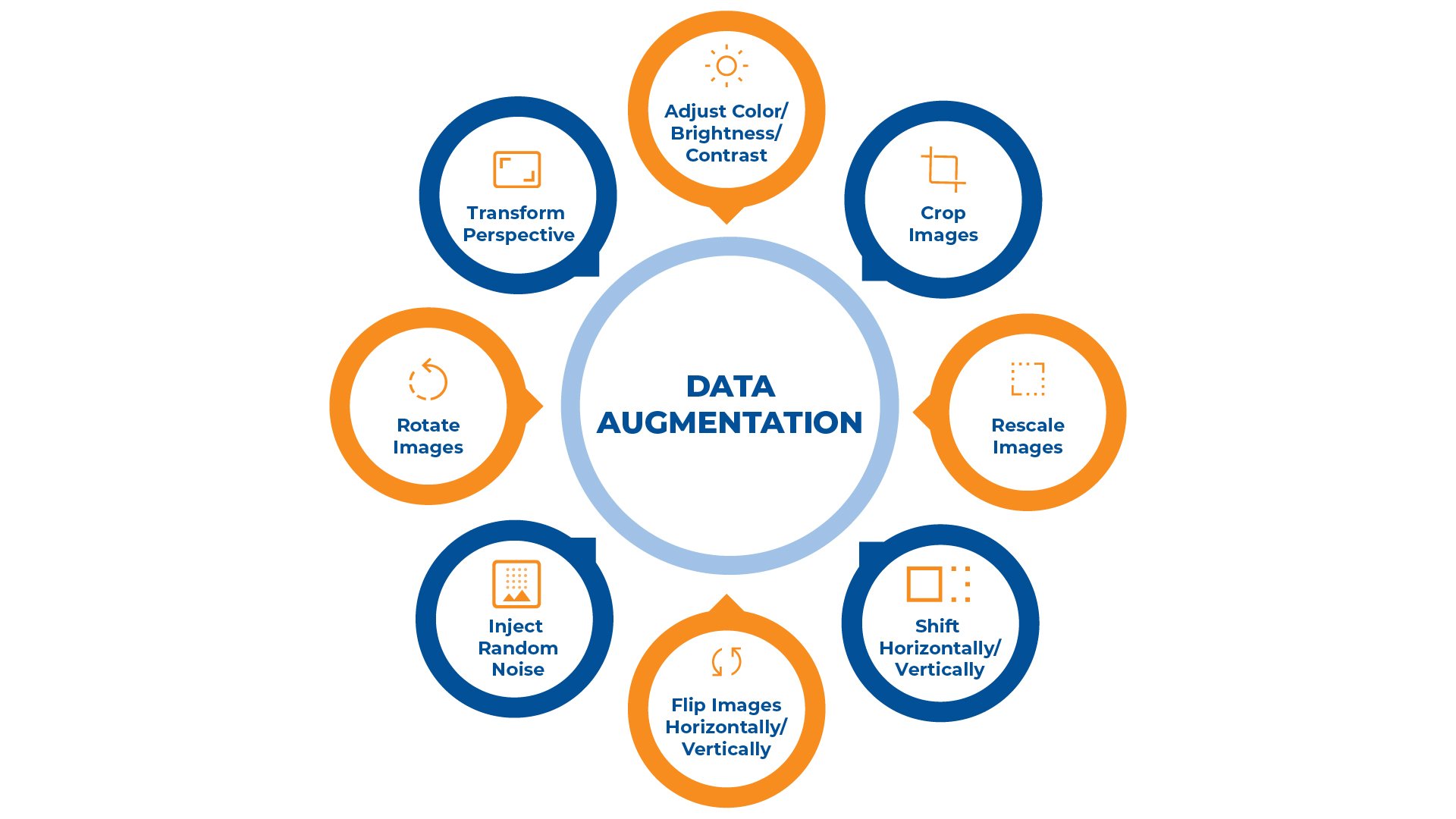
What is Data augmentation? Well, it is a technique to increase the diversity of your training set by applying random but realistic modifications to data. These modifications may include:
- Rotating the image by a certain angle
- Flipping the image horizontally or vertically
- Scaling the image up or down
- Cropping a portion of the image
- Changing the color attributes of the image
For text data, it might include changing synonyms or the order of words without altering the meaning.

Importance and Benefits
Data augmentation is crucial in machine learning, particularly for preventing overfitting, when a model performs well on training data but poorly on new, unseen data. By expanding your dataset with augmented data, you achieve several benefits:
- Increases the amount of training data and its variability
- Enhances model generalization
- Reduces model sensitivity to specific features
Additionally, it can be critical when training data is scarce, enabling effective model training without collecting more data.

Types of Data Augmentation
Data augmentation methods vary by medium, each enhancing an existing dataset’s size and variability. These methods introduce perturbations or transformations that help to make your models more generalizable and robust to changes in input data.
Image Data Augmentation
For your image datasets, data augmentation can include a range of transformations applied to original images. These manipulations often include:
- Rotations: Modifying the orientation of images.
- Flips: Mirroring images horizontally or vertically.
- Scaling: Enlarging or reducing the size of images.
- Cropping: Extracting subparts of images for training.
- Color Jittering: Adjusting image colors by changing brightness, contrast, saturation, and hue.
Did you know?
Google employs various data augmentation techniques, such as cropping, rotating, and color adjustments, to improve the performance of their image recognition algorithms. These algorithms are used for features like automatic photo tagging and organizing, ensuring that the model can accurately recognize and categorize images across a diverse array of lighting conditions, angles, and compositions.
Text Data Augmentation
When dealing with text, you can augment your data by altering the textual input to generate diverse linguistic variations. These alterations include:
- Synonym Replacement: Swapping words with their synonyms to preserve meaning while altering the sentence structure.
- Back Translation: Translating text to a different language and back to the original language.
- Random Insertion: Adding new words that fit the context of the sentence.
- Random Deletion: Removing words without distorting the sentence’s overall sense.

Audio Data Augmentation
To enhance your audio datasets, consider applying these common audio data augmentation techniques:
- Noise Injection: Adding background noise to audio clips to mimic real-life scenarios.
- Time Stretching: Changing the speed of the audio without affecting its pitch.
- Pitch Shifting: Altering the pitch of the audio, either higher or lower.
- Dynamic Range Compression: Reducing the volume of loud sounds or amplifying quiet sounds to normalize audio levels.
Did you know?
Spotify employs audio data augmentation to refine its music recommendation algorithms. This involves modifying audio tracks in various ways, such as altering pitch or speed, to train the models in recognizing and categorizing a wide range of musical styles and qualities. This technique significantly enhances user experience by ensuring personalized and accurate music suggestions.
Read More – Everything You Need to Know About Building a GPT Models
Techniques and Methods
Data augmentation techniques are essential in improving the performance of your machine learning models by increasing the diversity of your training set. This section guides you through several key techniques that you can apply.
Geometric Transformations
You can use geometric transformations to alter the spatial structure of your image data. These include:
- Rotation: Rotating the image by a certain angle.
- Translation: Shifting the image horizontally or vertically.
- Scaling: Zooming in or out of the image.
- Flipping: Mirroring the image either vertically or horizontally.
- Cropping: Removing sections of the image.

Photometric Transformations
Photometric transformations adjust the color properties of images to create variant data samples. Consider the following:
- Adjusting Brightness: Changing the light levels of an image.
- Altering Contrast: Modifying the difference in luminance or color that makes an object distinguishable.
- Saturation Changes: Varying the intensity of color in the image.
- Noise Injection: Adding random information to the image to simulate real-world imperfections.
Random Erasing
Random erasing is a practice where you randomly select a rectangle region in an image and erase its pixels with random values. This strategy encourages your model to focus on less prominent features by removing some information.
Tools
Several tools and libraries can assist you with data augmentation:
- Python Libraries: Libraries such as imgaug and Augmentor provide comprehensive sets of pre-built augmentation methods for ease of use.
- Deep Learning Frameworks: Frameworks like TensorFlow and PyTorch include modules and functions specifically designed for data augmentation.
Implementation Strategies
In implementing data augmentation, you need to decide between augmenting your data offline before training or online during the training process, as well as tailor strategies for deep learning applications.
Offline vs. Online Augmentation
Offline Augmentation: Here, you augment your dataset prior to training.
- Pros:
- Predictable increase in dataset size.
- One-time computational cost.
- Cons:
- Increased storage requirements.
- Limited variation compared to online methods.
Online Augmentation: This approach applies random transformations as new batches of data are fed into the model during training.
- Pros:
- Endless variation in data.
- More efficient storage usage.
- Cons:
- Higher computational load during training.
- Potentially slower training per epoch.

Data Augmentation in Deep Learning
For deep learning, augmentation should complement the model’s complexity.
- Image Data:
- Rotation, Scaling, Cropping: These basic transformations can help the model generalize better from different angles and sizes of objects.
- Color Jittering: Adjusting brightness, contrast, and saturation to make the model robust against lighting conditions.
- Text Data:
- Synonym Replacement: Swapping words with their synonyms can broaden the model’s understanding of language nuances.
- Back-translation: Translating text to another language and back to the original can create paraphrased versions, enhancing the model’s grasp of different expression forms.
- Audio Data:
- Noise Injection: Adding background noise trains the model to focus on the relevant parts of the audio.
- Pitch Shifting: Varying the pitch helps the model recognize speech patterns across different voice pitches.
In each case, carefully choose augmentation techniques that maintain the integrity of the data. Too much alteration can lead to misleading or incorrect model training.

Challenges and Limitations
In addressing the challenges and limitations of data augmentation, you must consider overfitting, computational demands, and the relevance of the augmented data.
| Risk |
Description |
| Overfitting |
Overfitting occurs when augmented data closely resembles the original dataset, leading to a model that performs well on training data but poorly on unseen data. It’s crucial to maintain diversity in augmented data to prevent overfitting. |
| Computational Costs |
Data augmentation increases the size of the training dataset, straining computational resources and extending training times. Evaluating the trade-offs between improved model performance and increased computational overhead is essential. |
| Data Relevance |
Ensuring the relevance of augmented data is crucial for effective model training. Irrelevant or misleading examples can degrade model performance. Choosing augmentation techniques that make sense for the specific data and use case is important. |
Applications in Machine Learning
Data augmentation is a technique that expands your dataset’s size and diversity without collecting new data. It manipulates your existing data to create varied scenarios, helping algorithms better generalize to unseen data.
Natural Language Processing
In Natural Language Processing (NLP), data augmentation can significantly enhance model performance. For example, you can use synonym replacement to swap words with their synonyms, or back-translation for translating text to another language and then back to the original language, each generating additional training examples. These methods enrich your language model’s understanding of the context and different phrasings with the same meaning.
Computer Vision
For Computer Vision, augmentation techniques include random transformations like rotation, flipping, scaling, and cropping of images. They force your model to learn from different perspectives and scales of objects. You can also apply color jitter to adjust brightness, contrast, and saturation, making your model robust to various lighting conditions.
Speech Recognition
In Speech Recognition, data augmentation is key to achieving models that can understand speech in noisy environments. You can add audio noise, such as background chatter or street sounds, or apply time stretching to alter the speed of the speech. These manipulations train your model to identify spoken words across a wide range of acoustic settings.
Choose Kanerika as your Partner
Kanerika can be your ideal partner for data-related projects due to its comprehensive data analytics, big data solutions, and artificial intelligence expertise. Their proven track record in delivering sophisticated data processing and analysis solutions makes them well-equipped to handle the complexities of big data, ensuring that your business can extract maximum value from its data assets.
With a team of highly skilled data scientists, engineers, and analytics experts, Kanerika leverages the latest technologies and methodologies to provide insights that drive strategic decision-making. Their commitment to innovation and a deep understanding of industry-specific challenges allow them to tailor solutions that meet and exceed client expectations. Whether through predictive analytics, data visualization, or machine learning models, partnering with Kanerika means accessing a wealth of knowledge and expertise to transform data into a competitive advantage.
Know more about our Business Transformation Through AI/ML Services
FAQs
What is meant by data augmentation?
Data augmentation is like taking existing photos and making slight changes to them, like rotating them, cropping them, or adjusting their brightness. This creates new, similar versions of your data without needing to collect more actual data. It helps machine learning models learn better by exposing them to a wider variety of examples.
What is augmentation with an example?
Augmentation means adding something to make it better or more effective. It’s like adding more ingredients to a recipe to make it more flavorful. For example, in machine learning, we augment data by adding variations to existing images, like rotating them or changing their brightness, to make our AI model more robust.
What is data augmentation in NLP?
Data augmentation in NLP is like adding more ingredients to your recipe to make it richer and more flavorful. It involves creating synthetic data from existing text by techniques like paraphrasing, replacing words with synonyms, or introducing noise. This helps train NLP models on a wider variety of data, leading to better performance and robustness.
What are the techniques of data augmentation?
Data augmentation is a clever way to expand your training dataset without collecting more data. It involves applying various transformations to existing data, like flipping images, adding noise, or changing colors, to create new, slightly different versions. This helps your model learn more robustly and generalize better to unseen data.
What is the principle of data augmentation?
Data augmentation is like taking a single photo and creating variations of it, like rotating it, flipping it, or adding noise. This helps train AI models by expanding the dataset, giving them more diverse examples and ultimately improving their performance. Essentially, it’s a way to “trick” the model into learning from more data than you actually have.
Is data augmentation an algorithm?
Data augmentation isn’t a single algorithm, but rather a collection of techniques used to increase the size and diversity of your training data. It involves modifying existing data in various ways, like flipping images, adding noise, or changing colors, to create new, synthetic data points. Essentially, it’s a strategy, not a specific algorithm.
How generative AI is used in data augmentation?
Generative AI acts like a creative artist for your data. It uses learned patterns to generate new, realistic data points that resemble your existing dataset. This expands your dataset, helping train AI models more effectively and address issues like limited data availability or class imbalance. Think of it as adding more brushstrokes to your data painting!
What is the difference between data augmentation and preprocessing?
Data augmentation artificially expands your dataset by creating variations of existing data, like flipping images or adding noise. Preprocessing, on the other hand, prepares your data for analysis by cleaning it, transforming it into a usable format, and standardizing it. Think of augmentation as making more copies of your data while preprocessing is like tidying up your data before you use it.
Does data augmentation reduce overfitting?
Data augmentation helps reduce overfitting by artificially expanding your training dataset. This combats overfitting by introducing more variations of your existing data, preventing the model from learning too closely to specific training examples and making it more robust to unseen data. In essence, it helps your model see the world from multiple angles, leading to better generalization.

